1) The Question, the Scouts, and the Newsroom
Maya asks an AI: “What teas help with sleep?”
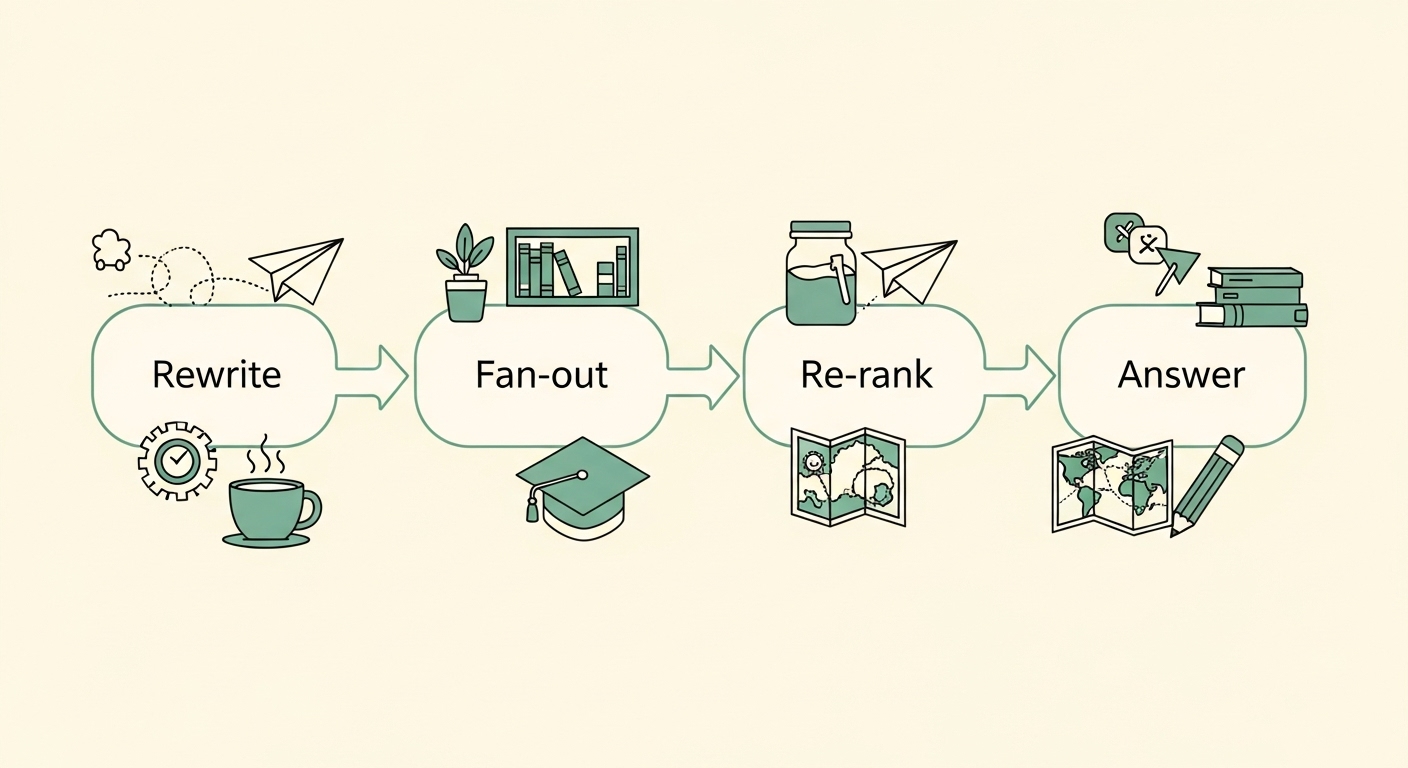
Behind the scenes, the AI doesn’t just run one search. It spins up several versions of the question like “teas for insomnia,” “bedtime herbal blends,” “caffeine‑free sleep tea” and sends them out in parallel like ten quick scouts. That’s fan‑out optimization: many small queries instead of one big bet.
The scouts come back with links, snippets, and data. A stricter referee (a re‑ranker) reads everything and says, “These five pieces are closest to what the user actually wants.” The AI then writes a short answer using the best evidence and, ideally, shows sources.
Why this matters to Maya: If her page only talks about “bedtime blends” but never mentions “sleep tea” or “insomnia,” some scouts may skip her. If her content is muddled or slow to load, the referee’s going to pass.
Plain takeaway: AI search is a pipeline:
rewrite → fan‑out → re‑rank → answer. You “rank” by being easy to fetch, easy to understand, and easy to trust at each step.
2) What “rank” Means in AI Answers
Before the scouts can even find Maya, crawlers have to read her site. Crawlers are automated visitors with name badges like Googlebot, GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, CCBot (Common Crawl), and others. They follow links, read sitemaps, and respect your house rules:
- robots.txt at your site’s root (broad allow/deny)
- <meta name="robots"> tags in HTML (page‑level rules)
- X‑Robots‑Tag HTTP headers (great for PDFs/images)
Maya checks her rules the same way she’d check a shop sign: Are we open? To whom? For what?
In this world, ranking ≠ magic. It’s: easy to fetch, easy to understand, easy to trust. Maya sketches a plan: make her pages crawlable, speak the user’s language (and synonyms!), and show real expertise with concise, verifiable claims.
3) The Door Policy (robots.txt + Cloudflare)
Before scouts can even find her, crawlers need to be let in. Maya checks two things:
a) Her house rules (/robots.txt):
She adds clear directives for the bots she’s okay with (Googlebot for search; optional AI‑specific agents like GPTBot, PerplexityBot, and Google‑Extended if she wants to permit their AI use). If she prefers to opt out of certain AI uses, she can disallow those agents while keeping regular search open.
She adds clear directives for the bots she’s okay with (Googlebot for search; optional AI‑specific agents like GPTBot, PerplexityBot, and Google‑Extended if she wants to permit their AI use). If she prefers to opt out of certain AI uses, she can disallow those agents while keeping regular search open.

User-agent: Googlebot
Allow: /
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
Sitemap: https://example.com/sitemap.xml
User-agent: Googlebot
Allow: /
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
Sitemap: https://example.com/sitemap.xml
(“Google‑Extended” is a control token for Google’s AI models; it doesn’t replace normal Googlebot crawling. Use it if you specifically want to opt out of Gemini training/grounding. OpenAI’s GPTBot, ClaudeBot, and PerplexityBot can likewise be allowed or disallowed via robots.)


b) The Bouncer (Cloudflare):
Inside Cloudflare’s dashboard there’s a
Block AI bots toggle. If Maya wants AI assistants to read her guides, she sets it
off. If she wants to keep them out, she flips it
on and can rely on network‑level blocking (including for some “unverified” crawlers), which goes beyond the voluntary nature of robots.txt compliance.
Cloudflare DocsReality check: Not every bot plays nice with robots.txt. That’s why Cloudflare added features like AI Labyrinth (a honeypot maze for misbehaving crawlers) and AI Audit (visibility + controls over AI services touching your site). If you plan to allow AI bots, leave trap‑style features off; if you plan to block, they help.
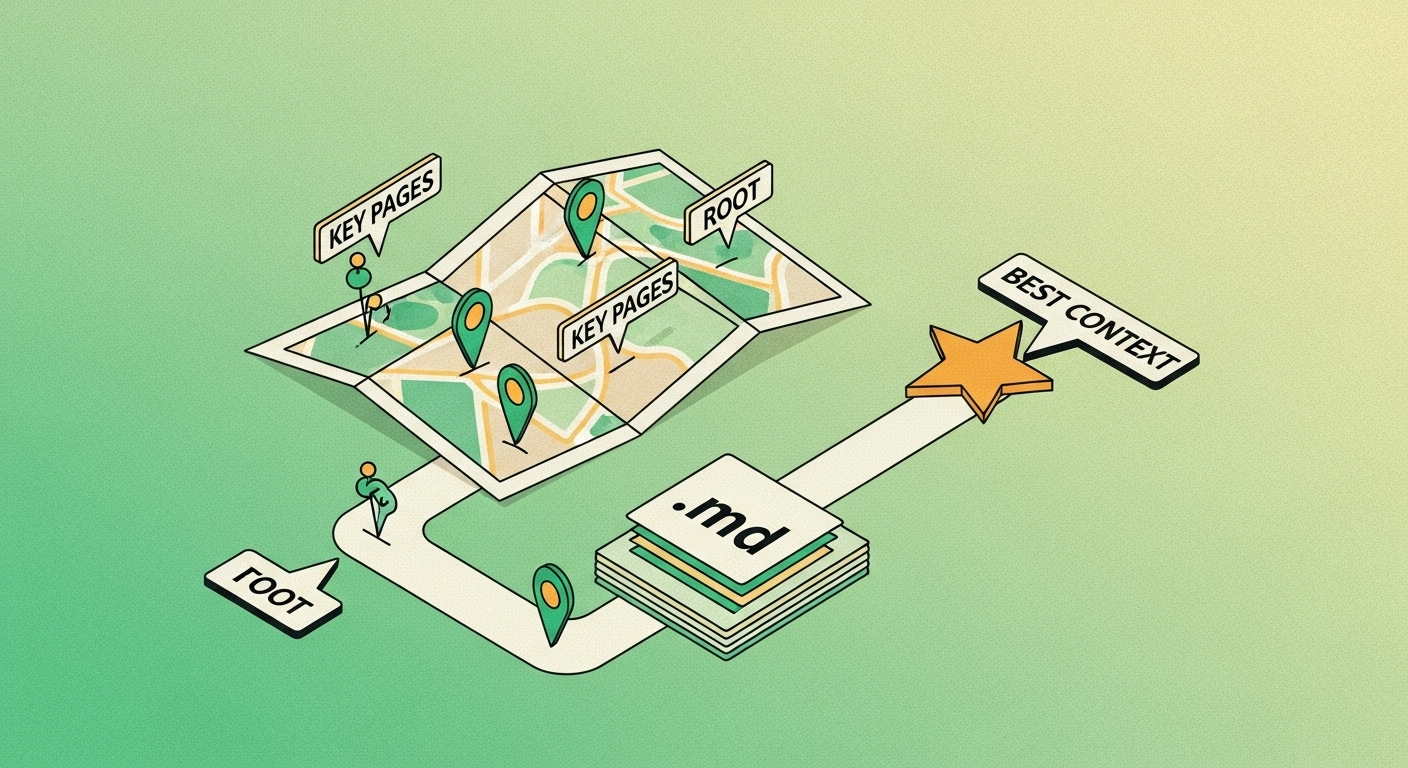
4) The Map for Machines (introducing llms.txt)
Now Maya realizes: Even if bots can enter, how do they quickly understand what matters on her site?
Enter
/llms.txt, a
proposed open standard by
Jeremy Howard. It’s a simple
Markdown file at your site root that gives LLMs a curated, compact guide: what your site is about, which pages to read, and (optionally) clean
.md mirrors of important pages so models can ingest them without UI clutter. It’s designed mainly for
inference time (the moment a user asks an AI about you), and it
complements robots.txt/sitemaps rather than replacing them.
That one page gives the scouts a map, not just a door. (Think of sitemaps as “everything we have,” while llms.txt says “start here for the best context”.)
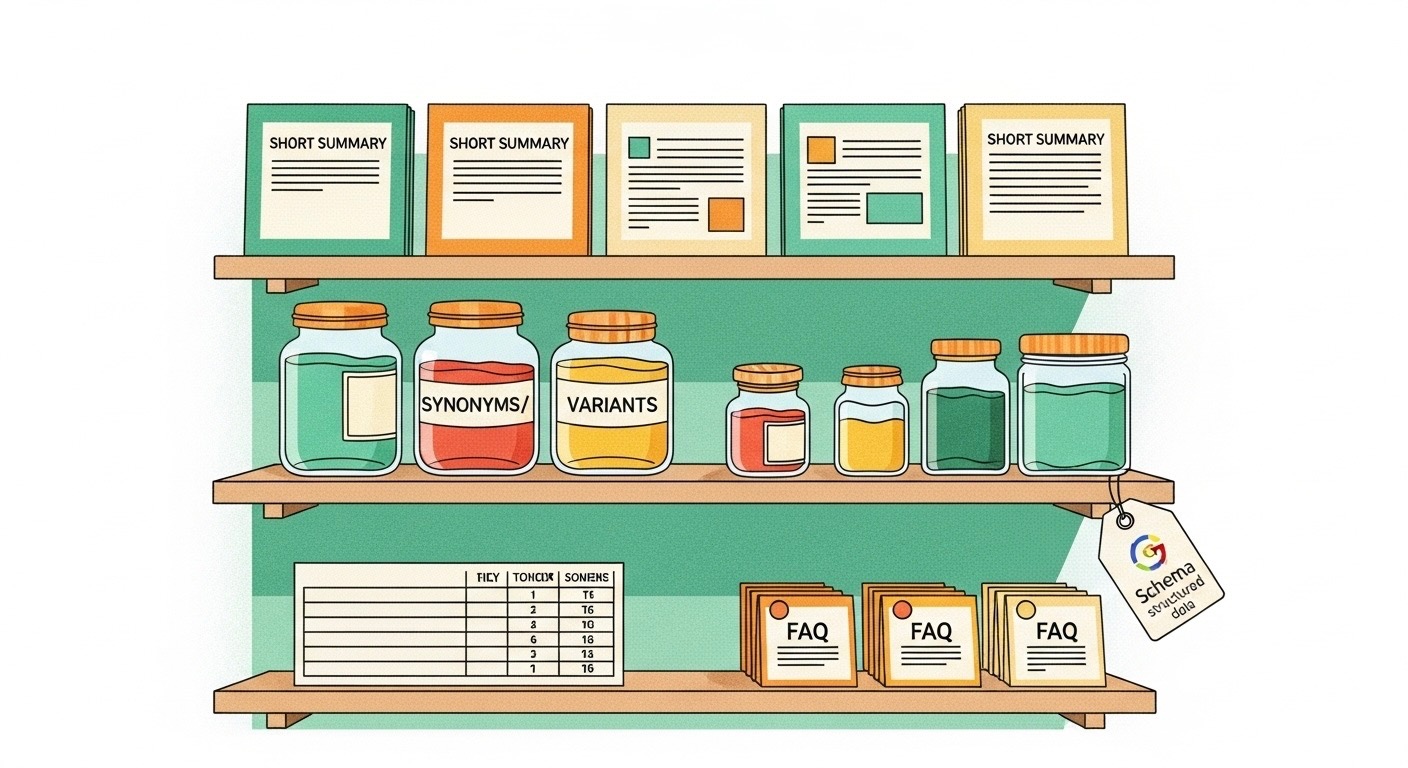
5) Shelves the Referee Loves (Content That Re‑Ranks Well)
With the door open and the map in place, Maya tidies the shelves:
- Answer‑first intros. Every guide begins with a crisp 2–4 sentence summary (the stuff assistants quote).
- Synonyms = more scouts find you. If the page is about sleep tea, also use bedtime blend, insomnia tea, caffeine‑free nighttime tea in natural places.
- Structure helps machines. Tables for dosage/taste/contraindications; short FAQs to match common sub‑questions.
- Structured data (Schema.org). She adds appropriate markup (Article/FAQ/Product/Organization) so machines parse her entities cleanly.
6) The Five‑Minute Keyword Storm: Maya’s Shortlist Machine
Maya’s team drops keyword data into Anion’s in‑app workflow, sometimes 80,000 keywords in a single file. No human can sensibly pick the best 5 to 10 from that pile, so the workflow does the heavy lifting:
- Clean & dedupe. First pass scrubs unnecessary terms and collapses duplicates/near‑duplicates. That still leaves 50,000+ viable phrases, too many to judge by hand.
- Fit & score to the site. We align each keyword to the actual website content and intent, then score it with market signals: volume, competition/difficulty, and trend to produce a single impact score.
- Cluster variants. Synonyms and phrasing twins roll up together (“sleep tea” ≈ “tea for insomnia”), so we’re comparing ideas, not just strings.
- Shortlist in under five minutes. The storm settles into roughly 0.3% of the original list from 80,000 to about 240 high‑impact candidates, each with built‑in analytics (competition, difficulty, volume) so planning is obvious.
- The “full‑score” tip. If the team wants to be ultra‑selective, filtering to only full‑score terms shrinks the list even further, often just a handful, making it trivial to choose the final 5 to 10.
7) Putting It All Together (Maya’s Quick Checklist)
If you want AI assistants to see your content
- In Cloudflare, set Block AI bots = Off. Cloudflare Docs
- Allow the AI bots you choose in robots.txt (e.g., GPTBot, ClaudeBot, PerplexityBot, Google‑Extended).
- Publish a helpful /llms.txt that links to LLM‑friendly .md versions of your best pages. llms-txt
- Use structured data and answer‑first writing so re-rankers love you. Google for Developers
If you prefer to keep AI crawlers out
- In Cloudflare, set Block AI bots = On. Cloudflare Docs
- Disallow the AI agents you don’t want via robots.txt. (Normal search can stay open.)
- Remember: robots.txt is advisory to bots, so network‑level controls matter. Cloudflare Docs
8) The Quiet Epilogue
A month later, when someone asks an AI about sleep teas, more answers point to Maya’s clear, well‑mapped pages. She didn’t trick the system, she helped it: opened the right door, left a map, arranged the shelves, and let the scouts do what they do best.
Just like Maya, you can guide AI to call out your products. Anion can help you open the right doors, organize your content, and appear in your audience’s AI results.
Get in touch today.










.png)


